Interactive Use of nprcgenekeepr
An R Package for the Genetic Management of Colonies
Source:vignettes/a2interactive.Rmd
a2interactive.RmdIntroduction
This tutorial demonstrates the major functions used within the Shiny application provided by the nprcgenekeepr package and provides sufficient insight into those functions that they may be used independently.
This tutorial is primarily directed toward someone with experience using R who wants to better understand how the Shiny application works or to perform some actions not directly supported by the Shiny application.
Please provide any comments, questions, or bug reports through the GitHub issue tracker at https://github.com/rmsharp/nprcgenekeepr/issues.
Installation and Help
You can install nprcgenekeepr from GitHub with the following code.
install.packages(nprcgenekeepr)
## Use the following code to get the development version
# install.packages("devtools")
# devtools::install_github("rmsharp/nprcgenekeepr")All missing dependencies should be automatically installed.
You can get help from the R console with
?nprcgenekeeprThe help provided by this (nprcgenekeepr.R) needs to be more complete and include links to the tutorials.
Reading in a Pedigree
A pedigrees can be imported using either Excel worksheets or text files that contain all of the pedigree information or using either Excel worksheets or text files that contain a list of focal animals with the remainder of the pedigree information is pulled in through the LabKey API.
This tutorial will use a pedigree file that can be created using the makeExamplePedigreeFile function as shown below. The function makeExamplePedigreeFile both saves a file and returns the full path name to the saved file, which we are saving into the variable pedigreeFile. Note: the user will select where to store the file.
library(nprcgenekeepr)
pedigreeFile <- makeExamplePedigreeFile()This writes ExamplePedigree.csv to a place you select within your file system.
You use the file name provided by the makeExamplePedigreeFile function to tell read.table what file to read.
breederPedCsv <- read.table(pedigreeFile,
sep = ",", header = TRUE,
stringsAsFactors = FALSE
)
breederPedCsv$fromCenter <- "TRUE"
breederPedCsv$fromCenter[
suppressWarnings(sample(
which(is.na(breederPedCsv$sire) &
is.na(breederPedCsv$dam)),
round(0.8 * length(which(
is.na(breederPedCsv$sire) &
is.na(breederPedCsv$dam)
)))
))
] <- "FALSE"Note the number of rows read. Each row represents an individual within the pedigree.
nrow(breederPedCsv)## [1] 3694The next step is to put the information read from the file into a pedigree object. This is done with the qcStudbook function, which examines the file contents and tests for common pedigree errors.
You can see the errors that can be detected by qcStudbook by returning the empty error list with getEmptyErrorLst(). We are not showing the output of the function call now because later in this tutorial we will explore errors in more depth.
qcStudbook can take five arguments sb, minSireAge and minDamAge (in years), reportChanges, and reportErrors. However, all but sb have default values and only the sb argument is required.
It is prudent to ensure that parents are at least of breeding age,
which is species and sex specific. Leaving minSireAge and
minDamAge blank (their default, NULL) looks up the
species-specific breeding age for each sex; a number overrides that
sex’s floor. I have set both to 2 years here.1
breederPed <- qcStudbook(breederPedCsv, minSireAge = 2L, minDamAge = 2L)If qcStudbook reports an error, change the call by adding the reportErrors argument set to TRUE and examine the returned object. More on this is presented in the Pedigree Errors section.
Identifying Focal Animals
You may want to focus your work on a focal group of animals. This can be done by reading in a list of animal IDs that make up the focal group and use that list to update the pedigree. Alternatively you can created a list of animal IDs based on criteria you have selected.
For example, to select living animals at the facility with at least one parent, the following can be used.
focalAnimals <- breederPed$id[!(is.na(breederPed$sire) &
is.na(breederPed$dam)) &
is.na(breederPed$exit)]
print(stri_c(
"There are ", length(focalAnimals),
" animals in the vector _focalAnimals_."
))[1] “There are 327 animals in the vector focalAnimals.”
As can be seen, these animals have at least one parent and have not left the facility.
## id sire dam exit
## 1669 01QRQ4 VDBGDP TH7HTY <NA>
## 1743 CLSVU6 ULV9M7 SUFWJI <NA>
## 1887 1SPLS8 U9APLW 142GKP <NA>
## 1934 5IAFMK U4YSS5 WVE6Y4 <NA>
## 2072 HLQ9SY UI3RFL VEWC1E <NA>
## 2234 XFWVVX U3MFSZ L4LM1F <NA>
## 2337 6X6BG9 ENI6HX IUF0HC <NA>
## 2377 B228Q6 UEUIRJ CBSIAA <NA>
## 2378 B2CKHA ENI6HX WBFBR5 <NA>
## 2383 BCJJKN UA379T JPVAT3 <NA>We indicate that these are the animals of interest by using the setPopulation function. This function simply sets a column named population2 to the logical value of TRUE if the row represents an animal in the list and FALSE otherwise.
The first line of code below sets the population column and the second counts the number of rows where the value was set to TRUE.
breederPed <- setPopulation(ped = breederPed, ids = focalAnimals)
nrow(breederPed[breederPed$population, ])## [1] 327The IDs used to populate the population flag can be used to trim the pedigree so that it contains only those individuals who are in the ID list or are ancestors of those individuals.
trimmedPed <- trimPedigree(focalAnimals, breederPed)
nrow(breederPed)## [1] 3694
nrow(trimmedPed)## [1] 704The trimPedigree function has the ability to remove those ancestors that do not contribute genetic information. Uninformative founders are those individuals who are parents of only one individual and who have no parental information. (Currently genotypic information is ignored by trimPedigree).
trimmedPedInformative <- trimPedigree(focalAnimals, breederPed,
removeUninformative = TRUE
)
nrow(trimmedPedInformative)## [1] 509We can find all of the animals that are in the trimmed pedigree but are not focal animals.
nonfocalInTrimmedPed <- trimmedPed$id[!trimmedPed$id %in% focalAnimals]
length(nonfocalInTrimmedPed)## [1] 377We can see which of these 377 are and are not parents. We will first make sure we have all of the parents by getting our list of parents from the entire pedigree. We then demonstrate that they are all in the trimmed pedigree.
allFocalParents <- c(
breederPed$sire[breederPed$id %in% focalAnimals],
breederPed$dam[breederPed$id %in% focalAnimals]
)
trimmedFocalParents <- c(
trimmedPed$sire[trimmedPed$id %in% focalAnimals],
trimmedPed$dam[trimmedPed$id %in% focalAnimals]
)
all.equal(allFocalParents, trimmedFocalParents) # Are the IDs the same?## [1] TRUEHowever, not all of the animals in the trimmed pedigree are either the focal animals or their parents. They are more distant ancestors as we will show.
notFocalNotParent <-
trimmedPed$id[!trimmedPed$id %in% c(focalAnimals, allFocalParents)]
length(notFocalNotParent)## [1] 187Since the trimming process is supposed to retain the focal animals and their ancestors, we will leave it as an exercise for you to demonstrate that at least some of the remaining animals are grandparents of the focal animals. Hint: there are 490 grandparents in both the trimmed and the complete pedigree.
As you can see from the number of rows in the full pedigree (3694) versus the trimmed pedigree (704), trimmed pedigrees can be much smaller. Of the additional 377 animals, 182 provide genetic information while the others (195) are genetically uninformative.
As is shown below only 4 (0ZX29Q, 1QBKW9, 5PWJ0G, and Y3CJ5A) living animals are still in the colony but are not in the trimmed pedigree.3
unknownBirth <- breederPed$id[is.na(breederPed$birth)]
knownExit <- breederPed$id[!is.na(breederPed$exit)]
unknownBirthKnownExit <-
breederPed$id[is.na(breederPed$birth) | !is.na(breederPed$exit)]
knownPed <- breederPed[!breederPed$id %in% unknownBirthKnownExit, ]
otherIds <- knownPed$id[!knownPed$id %in% trimmedPed$id[is.na(trimmedPed$exit)]]
print(stri_c(
"The living animals in the pedigree that are not in the trimmed ",
"pedigree are ", get_and_or_list(otherIds), "."
))[1] “The living animals in the pedigree that are not in the trimmed pedigree are 0ZX29Q, 1QBKW9, 5PWJ0G, and Y3CJ5A.”
Age Sex Pyramid Plot
You can examine the population structure using an age-sex pyramid plot with a single function. We will limit our view to just the focal animals and their living relatives. This is appropriate for colony management because in addition to the genetic diversity we seek, we have to remain cognizant of the age and sex distributions within the colonies we manage.
getPyramidPlot(ped = trimmedPed[is.na(trimmedPed$exit), ])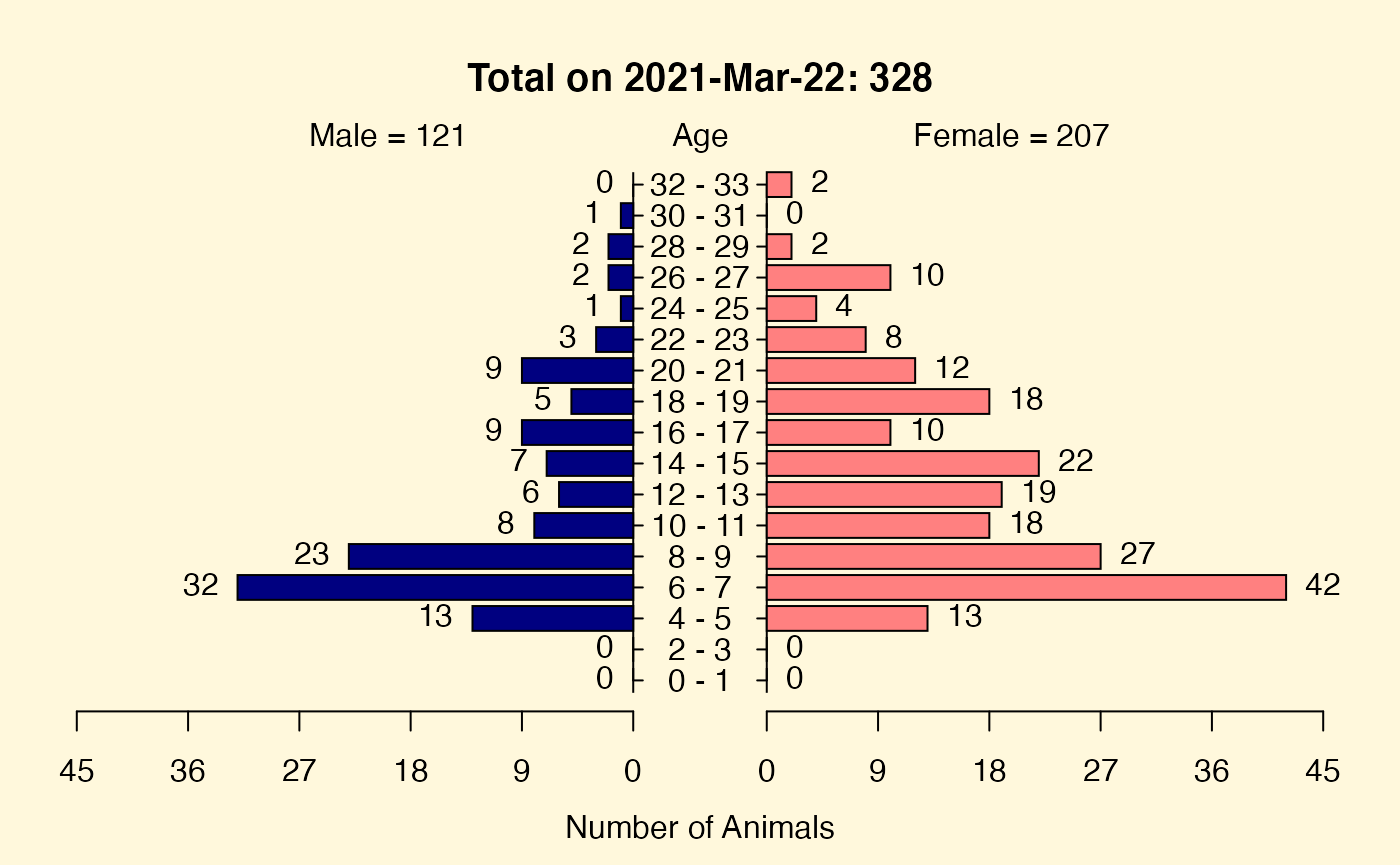
## 45 45## [1] 5.1 4.1 4.1 2.1Genetic Value Analysis
Your genetic value analysis must be carefully performed. The next three commands set up the entire pedigree for analysis. The first of these three commands set all of the pedigree members to be part of the population of interest by setting the population column to TRUE for all individuals.
ped <- setPopulation(breederPed, NULL)Note that a new pedigree object (ped) is being created.
probands <- ped$id[ped$population]
ped <- trimPedigree(probands, ped,
removeUninformative = FALSE,
addBackParents = FALSE
)The arguments to reportGV are all optional except for ped, but you may often want to use non-default values.
ped Pedigree information in data.frame format
guIter Integer indicating the number of iterations for the gene-drop analysis. Default is 1000 iterations
guThresh Integer indicating the threshold number of animals for defining a unique allele. Default considers an allele “unique” if it is found in only 1 animal.
pop Character vector with animal IDs to consider as the population of interest. The default is NULL.
byID Logical variable of length 1 that is passed through to eventually be used by alleleFreq(), which calculates the count of each allele in the provided vector. If byID is TRUE and ids are provided, the function will only count the unique alleles for an individual (homozygous alleles will be counted as 1).
geneticValue <- reportGV(ped,
guIter = 50L,
guThresh = 3L,
byID = TRUE,
updateProgress = NULL
)
summary(geneticValue)## The genetic value report
## Individuals in Pedigree: 3694
## Male Founders: 141
## Female Founders: 122
## Total Founders: 263
## Founder Equivalents: 241.84
## Founder Genome Equivalents: 164.01 +/- 0.04
## Live Offspring: 4052
## High Value Individuals: 1593
## Low Value Individuals: 729What happens if we limit our analysis to the trimmed pedigree? Remember that the trimmed pedigree still contains all of the genetic information that the full pedigree has for the focal animals.
trimmedGeneticValue <- reportGV(trimmedPed,
guIter = 50L,
guThresh = 3L,
byID = TRUE,
updateProgress = NULL
)
summary(trimmedGeneticValue)## The genetic value report
## Individuals in Pedigree: 327
## Male Founders: 3
## Female Founders: 17
## Total Founders: 20
## Founder Equivalents: 109.67
## Founder Genome Equivalents: 47.49 +/- 0.32
## Live Offspring: 321
## High Value Individuals: 233
## Low Value Individuals: 94It is clear that limiting your analysis to the animals of interest reduces the effort required to examine the animals of interest.
Detailed look at the Genetic Value Report object
The names of the object within the genetic value report object (trimmedGeneticValue) can be listed as shown in the next line of code.
names(trimmedGeneticValue)## [1] "report" "kinship" "gu" "fe"
## [5] "fg" "fgSE" "neGD" "neSexRatio"
## [9] "neVariance" "maleFounders" "femaleFounders" "nMaleFounders"
## [13] "nFemaleFounders" "total"The report object (an R dataframe) can in-turn be examined.
names(trimmedGeneticValue$report) ## column names## [1] "id" "sex" "age" "birth"
## [5] "exit" "population" "origin" "sire"
## [9] "dam" "indivMeanKin" "zScores" "gu"
## [13] "guSE" "totalOffspring" "livingOffspring" "parentage"
## [17] "value" "rank"
nrow(trimmedGeneticValue$report) ## Number of rows## [1] 327The report is more conveniently used as a separate object. The next section of code rounds some of the numerical values and converts all columns to characters for display as a table where only the first 10 lines are included.
rpt <- trimmedGeneticValue[["report"]]
rpt$indivMeanKin <- round(rpt$indivMeanKin, 5L)
rpt$zScores <- round(rpt$zScores, 2L)
rpt$gu <- round(rpt$gu, 5L)
rpt <- toCharacter(rpt)
names(rpt) <- headerDisplayNames(names(rpt))
knitr::kable(rpt[1L:10L, ]) # needs more work for display purposes.| Ego ID | Sex | Age (in years) | Birth Date | Exit Date | Breeding Colony Member | Origin | Sire ID | Dam ID | Individual Mean Kinship | Z-score (Mean Kinship) | Genome Uniqueness (%) | NA | Total Offspring | Living Offspring | NA | Value Designation | Rank |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KZM9RB | M | 30.1 | 1989-05-03 | NA | TRUE | UWTJQ0 | BLLUWW | 0.00329 | -2.30 | 92 | 2.618615 | 0 | 0 | one unknown parent | High Value | 1 | |
| CLSVU6 | F | 23.9 | 1995-08-02 | NA | TRUE | ULV9M7 | SUFWJI | 0.00951 | -1.18 | 90 | 2.857143 | 1 | 1 | one unknown parent | High Value | 2 | |
| 1SPLS8 | F | 7.9 | 2011-07-26 | NA | TRUE | U9APLW | 142GKP | 0.01066 | -0.97 | 84 | 3.331973 | 0 | 0 | one unknown parent | High Value | 3 | |
| WK89I9 | F | 21.1 | 1998-05-26 | NA | TRUE | U5QF9U | KZX47Z | 0.01212 | -0.71 | 80 | 3.499271 | 0 | 0 | one unknown parent | High Value | 4 | |
| 8YP6PA | M | 5.0 | 2014-07-04 | NA | TRUE | UD26S6 | PU7RSG | 0.01208 | -0.72 | 77 | 3.559982 | 0 | 0 | one unknown parent | High Value | 5 | |
| 01QRQ4 | F | 18.2 | 2001-04-04 | NA | TRUE | VDBGDP | TH7HTY | 0.00373 | -2.23 | 74 | 3.568570 | 0 | 0 | known | High Value | 6 | |
| IZDV8K | M | 7.7 | 2011-09-29 | NA | TRUE | U5B4PI | PI4VHT | 0.01173 | -0.78 | 74 | 3.568570 | 0 | 0 | one unknown parent | High Value | 7 | |
| R6HV9A | M | 22.1 | 1997-05-13 | NA | TRUE | HPSHXC | BCJJKN | 0.00625 | -1.77 | 73 | 4.783048 | 0 | 0 | known | High Value | 8 | |
| CFD12A | M | 20.8 | 1998-08-25 | NA | TRUE | U79BJ1 | WFQENR | 0.01139 | -0.84 | 71 | 3.525418 | 0 | 0 | one unknown parent | High Value | 9 | |
| 3MMZD4 | M | 12.2 | 2007-03-24 | NA | TRUE | K7900I | 5W3NTM | 0.00536 | -1.93 | 70 | 4.040610 | 0 | 0 | known | High Value | 10 |
We start the next lines of code by getting a fresh copy of the genetic value report since we changed all of the numeric values to characters in the last section to print the table. These lines demonstrate one way of extracting the component objects from the genetic value object.
rpt <- trimmedGeneticValue[["report"]]
kmat <- trimmedGeneticValue[["kinship"]]
f <- trimmedGeneticValue[["total"]]
mf <- trimmedGeneticValue[["maleFounders"]]
ff <- trimmedGeneticValue[["femaleFounders"]]
nmf <- trimmedGeneticValue[["nMaleFounders"]]
nff <- trimmedGeneticValue[["nFemaleFounders"]]
fe <- trimmedGeneticValue[["fe"]]
fg <- trimmedGeneticValue[["fg"]]It is informative to examine the distribution of genetic uniqueness, mean kinship, and z-scores (normalized mean kinship values).
Creation of the boxplot for the genetic uniqueness values is shown below.
gu <- rpt[, "gu"]
guBox <- ggplot(data.frame(gu = gu), aes(x = "", y = gu)) +
geom_boxplot(
color = "darkblue",
fill = "lightblue",
notch = TRUE, #| fig.alt: >
#| Histogram of time between eruptions for Old Faithful.
#| It is a bimodal distribution with peaks at 50-55 and
#| 80-90 minutes.
outlier.color = "red",
outlier.shape = 1L
) +
theme_classic() +
geom_jitter(width = 0.2) +
coord_flip() +
ylab("Score") +
ggtitle("Genetic Uniqueness")
print(guBox)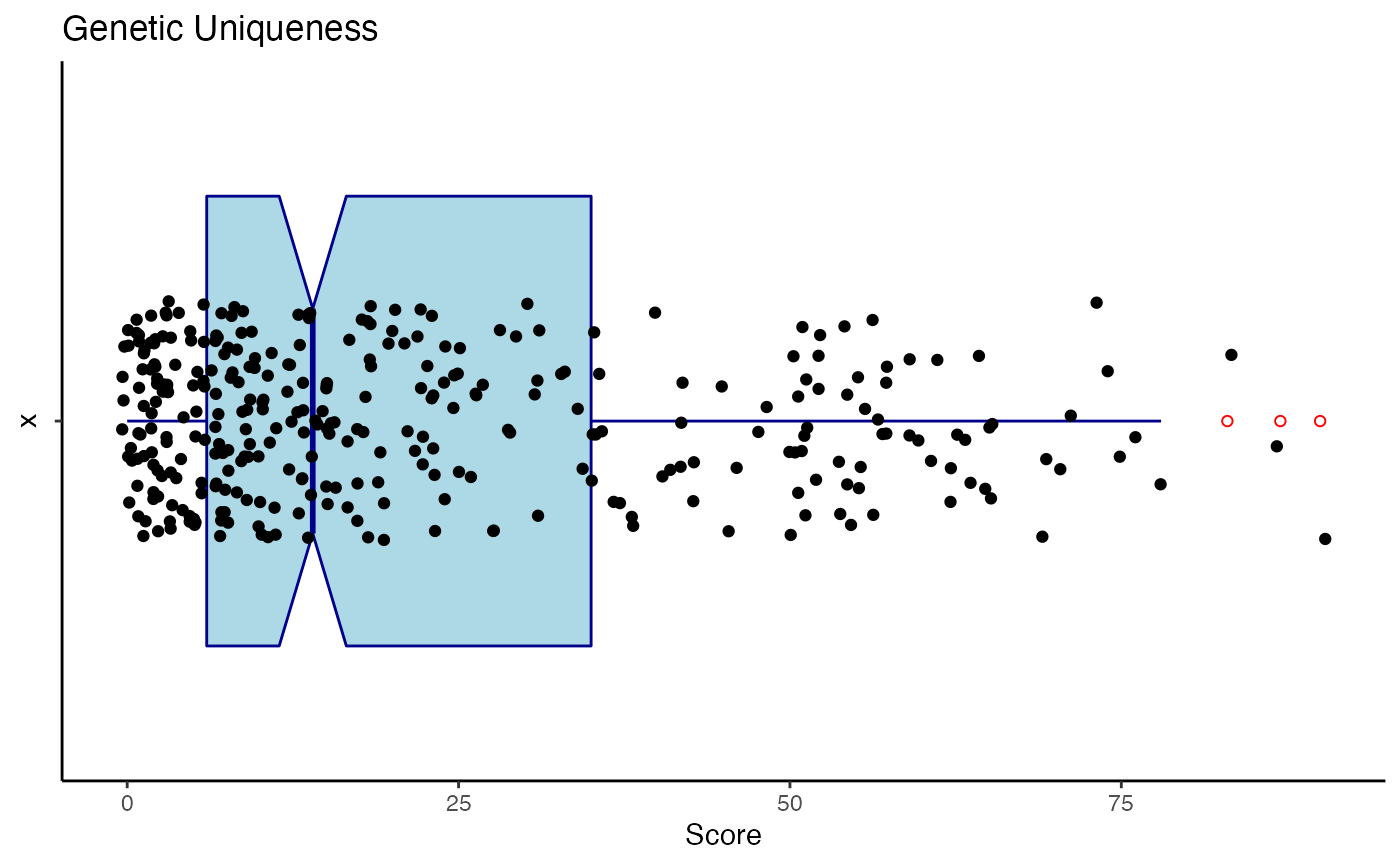
Extraction of the individual mean kinship values and their corresponding z-scores is shown in the next code chunk.
mk <- rpt[, "indivMeanKin"]
zs <- rpt[, "zScores"]Creation of boxplots for the mean kinship and z-scores is left as an exercise.
Breeding Group Formation
The primary purpose of nprcgenekeepr is to form breeding groups according to our best information regarding maintaining the genetic characteristics we desire and the realities associated with other animal husbandry needs.
There are several options you must consider when forming groups using nprcgenekeepr, which we will examine using code below.
- Animals used to form groups
- high-value: Randomly select from only high-value animals in genetic value analysis
- all: Randomly select from all animals in genetic value analysis
- candidates: Use candidate animals entered below to form groups
- Sex ratio
- Randomly assign animals without regard to sex
- Use a harem structure with one breeding male per group
- Specify the sex ratio between 0.5 and 10 (F/M)
- Whether or not to pre-populate (seed) groups with animals of your choice
- Number of groups to be formed
- Whether or not to ignore females at or above the minimum parent age
- Number of simulations used to search for the optimal group makeup
- Whether or not kinship coefficients are to be included in results
You decisions regarding each of the above options are expressed in a call to the function groupAddAssign. A complete description of the function and its arguments is available using the code shown below.
?groupAddAssignBelow is the descriptions of the function parameters extracted from the documentation near the time this tutorial was prepared.
candidates Character vector of IDs of the animals available for use in forming the groups. The animals that may be present in currentGroups are not included within candidates.
currentGroups List of character vectors of IDs of animals currently assigned to groups. Defaults to a list with character(0) in each sub-list element (one for each group being formed) assuming no groups are pre-populated.
kmat Numeric matrix of pairwise kinship values. Rows and columns are named with animal IDs.
ped Dataframe that is the ‘Pedigree’. It contains pedigree information including the IDs listed in candidates.
threshold Numeric value indicating the minimum kinship level to be considered in group formation. Pairwise kinship below this level will be ignored. The default values is 0.015625.
ignore List of character vectors representing the sex combinations to be ignored. If provided, the vectors in the list specify if pairwise kinship should be ignored between certain sexes. Default is to ignore all pairwise kinship between females.
minAge Integer value indicating the minimum age to consider in group formation. Pairwise kinships involving an animal of this age or younger will be ignored. Default is 1 year.
iter Integer indicating the number of times to perform the random group formation process. Default value is 1000 iterations.
numGp Integer value indicating the number of groups that should be formed from the list of IDs. Default is 1.
updateProgress Function or NULL. If this function is defined, it will be called during each iteration to update a shiny::Progress object.
harem Logical variable when set to TRUE, the formed groups have a single male at least minAge old.
sexRatio Numeric value indicating the ratio of females to males x from 0.5 to 20 by increments of 0.5.
withKin Logical variable when set to TRUE, the kinship matrix for the group is returned along with the group and score. Defaults to not return the kinship matrix. This maintains compatibility with earlier versions.
We will use the trimmedPed pedigree in our code.
For illustration purposes we are going to keep the numbers of candidates, groups, and iterations fairly small.
We will get first some animal IDs to use for our candidates by selecting animals at least 2 years old at the time this pedigree was sampled (01-01-2015).
candidates <- trimmedPed$id[trimmedPed$birth < as.Date("2013-01-01") &
!is.na(trimmedPed$birth) &
is.na(trimmedPed$exit)]
table(trimmedPed$sex[trimmedPed$id %in% candidates])##
## F M H U
## 184 96 0 0Our candidates are made up of 184 females and 96 males. The parameters currentGroups, threshold, ignore, minAge, sexRatio, withKin, and updateProgress are allowed to take their default values. The setting of the sexRatio parameter to 0 is ignored in the following call of the groupAddAssign function. This is consistent with the a value of 0 making little since in a breeding colony.
The empty seventh group at the bottom is evidence that all of the candidate animals could be placed in a group without exceeding the default value of 0.015625.
Harems
The following group assignments will be forming harem groups. This is
done by setting harem to . Setting iter to
100 or more will increase optimal composition of breeding groups
haremGrp <- groupAddAssign(
kmat = trimmedGeneticValue[["kinship"]],
ped = trimmedPed,
candidates = candidates,
iter = 10L,
numGp = 6L,
harem = TRUE
)
haremGrp$group## [[1]]
## [1] "S63QDN" "TQEMY6" "XYRDKV" "ZATMEE" "AW400C" "AR5U44" "CHK1ZX" "414N7M"
## [9] "EZ2F8A" "WLMGS1" "MYUMMX" "DHNQ1W" "1KJ2MG" "KZY6PD" "0SGJ12" "CS23RV"
## [17] "AP1YLW" "38K2SR" "VWC5ZH" "GTLA8R" "1CIRC9" "YLRNIK" "5KWNMZ" "83HQBN"
## [25] "465ERA" "Y6DB6L" "7NE2UT" "EX5K0S" "MTCAIG"
##
## [[2]]
## [1] "CHJ9D2" "T3QPW5" "XEC0M5" "YFCIHJ" "S222R3" "BKWE4D" "S3EBGZ" "8JUUJ9"
## [9] "72LYDE" "6X6BG9" "CRPXY7" "FB5L3N" "87AQLF" "QCENKM" "MX4J7G" "BCJJKN"
## [17] "WKY2SZ" "QRZK48" "01QRQ4" "SCFSBF" "AFZKBS" "WI38KZ" "DH9WJQ" "BS3RLE"
## [25] "Y0TCYX" "30J3CQ" "MFKT9C"
##
## [[3]]
## [1] "FX9E4X" "B228Q6" "CMMUKU" "7B9CA6" "N4NV8B" "MH88T6" "I5CI33" "M9PVG5"
## [9] "1SSCJC" "WNEAS6" "46ZHKN" "967Y3D" "2F6J3U" "E5Q33K" "C18V6I" "3YJIMV"
## [17] "N5QBWD" "AIHJ8Z" "1CZM30" "DI4AHD" "YTJ2UL" "SHG3RB" "AZ3L0D" "X694YR"
## [25] "1FAZ0K" "DRXMW4" "D4B0RM" "Z904TJ" "0XTZQ1" "GCBYDW" "FL170P" "50D77I"
##
## [[4]]
## [1] "Z25D52" "NK802Y" "IH1KPA" "PJ72W1" "Q8U9LB" "B134XZ" "RJ4JPC" "MKY9TK"
## [9] "S7IWWA" "QW2Z3R" "D9P18Y" "5W621W" "3GECJJ" "S056D5" "SH3FB7" "HE0SCR"
## [17] "H2J6UA" "TYEWF1" "WTE53B" "GIIEUD" "D33J06" "PU7RSG" "3SKITJ" "6F9FB8"
## [25] "W6MDVK" "J3F6PD" "R5AYJK" "Q7U139" "7RA57Q" "5EDLL7" "RVHVTZ" "WJXIH9"
## [33] "PVY432"
##
## [[5]]
## [1] "YDRD81" "G58RGY" "5ERY5Z" "1SPLS8" "6KWVRI" "321LLB" "K3TNHP" "TEACA3"
## [9] "2Z4YLY" "FJS7RQ" "9MG040" "JLFKV8" "N79QXB" "5EDIEE" "13B1QL" "QWKFBH"
## [17] "QCA36T" "WK89I9" "I8ABC7" "LYSLPP" "MB6NYQ" "1GF3GM" "DKIM6U" "99BMJW"
## [25] "KX0RJ3" "0HYZ23" "QQMBT1" "92UG4N" "GAS52W" "DPXEQE" "G25E3F" "PYPM1W"
## [33] "EMV4P6" "TXZUKC" "S5H1GC" "1QVS67" "CLSVU6" "LVYYNY" "5BPBUI"
##
## [[6]]
## [1] "XY2CK7" "F45799" "NN3GDQ" "KEA4QG" "LS184H" "9P0DES" "MPIQ4N" "B1WVCN"
## [9] "W5WIRP" "3DTD2N" "5IAFMK" "DCJJYS" "PI4VHT" "0X4W26" "FG0SFA" "7ZNY75"
## [17] "G8MCV7" "ZQXZYB" "PBAFJF" "ZPS15A" "ILVQVB" "ZH3YG1" "Q17CG3" "W0GUKI"
## [25] "F7I2ED" "AR17R5" "XFWVVX" "1VP3UC" "0IIAEN" "ESUIAF"
##
## [[7]]
## [1] NAWe can identify and list the males in each group with the following code.
## [[1]]
## [1] "S63QDN"
##
## [[2]]
## [1] "CHJ9D2"
##
## [[3]]
## [1] "FX9E4X"
##
## [[4]]
## [1] "Z25D52"
##
## [[5]]
## [1] "YDRD81"
##
## [[6]]
## [1] "XY2CK7"
##
## [[7]]
## logical(0)It is easy to notice that the male is listed first within each breeding group.
We can also see the number of animals and the sex ratios created in each group. Since these are harem groups the sex ratios are determined by the number of animals in the individual groups.
lines <- sapply(haremGrp$group, function(ids) {
paste0(
"Count: ", length(ids), " Sex Ratio: ",
round(calculateSexRatio(ids, trimmedPed), 2)
)
})
for (line in lines) print(line)## [1] "Count: 29 Sex Ratio: 28"
## [1] "Count: 27 Sex Ratio: 26"
## [1] "Count: 32 Sex Ratio: 31"
## [1] "Count: 33 Sex Ratio: 32"
## [1] "Count: 39 Sex Ratio: 38"
## [1] "Count: 30 Sex Ratio: 29"
## [1] "Count: 1 Sex Ratio: Inf"Examination of this table shows that of the 184 females 156 are included.
Controlling Sex Ratios
The following group assignments will be forming harem groups. This is done by setting harem to .
sexRatioGrp <- groupAddAssign(
kmat = trimmedGeneticValue[["kinship"]],
ped = trimmedPed,
candidates = candidates,
iter = 10L,
numGp = 6L,
sexRatio = 9.0
)
sexRatioGrp$group## [[1]]
## [1] "SHG3RB" "8TV4MT" "QRZK48" "D9P18Y" "414N7M" "SH3FB7" "0XTZQ1" "3YJIMV"
## [9] "BKWE4D" "83HQBN" "Z904TJ" "6KWVRI" "NN3GDQ" "KZM9RB" "BS3RLE" "5EDIEE"
## [17] "KEA4QG" "DRXMW4" "87AQLF" "2Z4YLY" "0X4W26" "ESUIAF" "1CIRC9" "WNEAS6"
## [25] "HLQ9SY" "1SPLS8" "PU7RSG" "S7IWWA" "S222R3" "5BPBUI" "WLMGS1" "J3F6PD"
## [33] "MPIQ4N" "WJXIH9" "G2GYST"
##
## [[2]]
## [1] "Y6DB6L" "XY2CK7" "1KJ2MG" "XEC0M5" "DHNQ1W" "KZY6PD" "5KWNMZ" "B228Q6"
## [9] "5EDLL7" "Y0TCYX" "CRPXY7" "G8MCV7" "GIIEUD" "R6HV9A" "W6MDVK" "CS23RV"
## [17] "1SSCJC" "01QRQ4" "MB6NYQ" "1CZM30" "WKY2SZ" "VWC5ZH" "PBAFJF" "Q7U139"
## [25] "CFD12A" "MYUMMX"
##
## [[3]]
## [1] "XYRDKV" "5XVTVH" "QCA36T" "RVHVTZ" "3SKITJ" "WK89I9" "FG0SFA" "DI4AHD"
## [9] "WTE53B" "XFWVVX" "C18V6I" "MH88T6" "321LLB" "YHHVC7" "TQEMY6" "Q17CG3"
## [17] "50D77I" "AFZKBS" "3DTD2N" "ZATMEE" "30J3CQ" "EMV4P6" "DPXEQE" "8JUUJ9"
## [25] "K7900I"
##
## [[4]]
## [1] "MKY9TK" "2F1IV1" "1QVS67" "MTCAIG" "1GF3GM" "YFCIHJ" "W0GUKI" "465ERA"
## [9] "EX5K0S" "6F9FB8" "YTJ2UL" "PVY432" "D33J06" "IZDV8K" "99BMJW" "AZ3L0D"
## [17] "R5AYJK" "N5QBWD" "NK802Y" "N79QXB" "46ZHKN" "WI38KZ" "72LYDE" "0HYZ23"
## [25] "3MMZD4"
##
## [[5]]
## [1] "DH9WJQ" "XL658N" "QQMBT1" "X694YR" "AIHJ8Z" "7RA57Q" "LVYYNY" "0IIAEN"
## [9] "1VP3UC" "Q8U9LB" "GCBYDW" "MX4J7G" "FL170P" "T38W6H" "PI4VHT" "S5H1GC"
## [17] "5ERY5Z" "JLFKV8" "ZQXZYB" "13B1QL" "7NE2UT" "GTLA8R" "PJ72W1" "DKIM6U"
## [25] "LN1DLY" "EZ2F8A" "G25E3F" "KX0RJ3" "7ZNY75" "LS184H" "9MG040" "ZH3YG1"
## [33] "N4NV8B" "B134XZ" "Z7NBA2"
##
## [[6]]
## [1] "38K2SR" "B2CKHA" "QCENKM" "AP1YLW" "CHK1ZX" "YLRNIK" "QWKFBH" "D4B0RM"
## [9] "GAS52W" "TXZUKC" "G58RGY" "967Y3D" "CLSVU6" "7D09WH" "1FAZ0K" "ILVQVB"
## [17] "B1WVCN" "RJ4JPC" "T3QPW5" "S3EBGZ" "AR17R5" "LYSLPP" "F7I2ED" "FJS7RQ"
## [25] "5PW7WT" "FB5L3N" "HE0SCR" "H2J6UA" "BCJJKN" "K3TNHP" "S056D5"
##
## [[7]]
## [1] "5IAFMK" "6X6BG9" "DCJJYS" "GDXWJ1" "JSAP3H" "TR5L57" "XC304E" "1E8KD1"
## [9] "5KFB90" "A6A1M1" "AEP5EG" "AW400C" "BW10CL" "CHJ9D2" "FTVE03" "IH1KPA"
## [17] "IRFJ09" "KXHGRH" "LMJWTN" "M9PVG5" "Q9LWGX" "RNQU14" "SCFSBF" "TEACA3"
## [25] "TYEWF1" "W5WIRP" "ZPS15A" "09LFE4" "2F6J3U" "3GECJJ" "3QHAFI" "55BPSE"
## [33] "7B9CA6" "8IG767" "9FRCIE" "ER464J" "FFGPS4" "FG6L7S" "NHWTJ9" "P7RBPI"
## [41] "TBCE78" "YI16QD" "4LHK19" "59NYZE" "5IYDXN" "6KLWVC" "80F2MI" "A98D7P"
## [49] "AZ4D19" "BTTHAJ" "CHSCFG" "EEGLWY" "FX9E4X" "G91ZM6" "I5CI33" "I8ABC7"
## [57] "J1R2EW" "LDND6J" "MFKT9C" "MQT080" "NSIC4I" "PHB6TE" "PYPM1W" "QRWYQZ"
## [65] "QW2Z3R" "RY1AZM" "WHQLH5" "WQUN84" "XX0GYV" "YP910X" "0SGJ12" "0V4SAC"
## [73] "0X1RZ9" "3YHBC1" "55VDSQ" "5W621W" "653J82" "6MEP2C" "76DIT4" "80KACX"
## [81] "92UG4N" "9P0DES" "B2YJJP" "CMMUKU" "E3JP0C" "E5Q33K" "F45799" "FLIZQI"
## [89] "GM371F" "MEUZ85" "PA9F3J" "SXSVEH" "TJN1AD" "WNKKW3" "XZH41H" "YDRD81"
## [97] "Z25D52" "ZDRSG0" "3P9BX6" "AR5U44" "DGZLV3" "S63QDN" "ZW2X4N"Again we can identify and list the males in each group with the following code.
## [[1]]
## [1] "8TV4MT" "KZM9RB" "HLQ9SY" "G2GYST"
##
## [[2]]
## [1] "XY2CK7" "R6HV9A" "CFD12A"
##
## [[3]]
## [1] "5XVTVH" "YHHVC7" "K7900I"
##
## [[4]]
## [1] "2F1IV1" "IZDV8K" "3MMZD4"
##
## [[5]]
## [1] "XL658N" "T38W6H" "LN1DLY" "Z7NBA2"
##
## [[6]]
## [1] "B2CKHA" "7D09WH" "5PW7WT"
##
## [[7]]
## [1] "GDXWJ1" "JSAP3H" "TR5L57" "XC304E" "1E8KD1" "5KFB90" "A6A1M1" "AEP5EG"
## [9] "BW10CL" "CHJ9D2" "FTVE03" "IRFJ09" "KXHGRH" "LMJWTN" "Q9LWGX" "RNQU14"
## [17] "09LFE4" "3QHAFI" "55BPSE" "8IG767" "9FRCIE" "ER464J" "FFGPS4" "FG6L7S"
## [25] "NHWTJ9" "P7RBPI" "TBCE78" "YI16QD" "4LHK19" "59NYZE" "5IYDXN" "6KLWVC"
## [33] "80F2MI" "A98D7P" "AZ4D19" "BTTHAJ" "CHSCFG" "EEGLWY" "FX9E4X" "G91ZM6"
## [41] "J1R2EW" "LDND6J" "MQT080" "NSIC4I" "PHB6TE" "QRWYQZ" "RY1AZM" "WHQLH5"
## [49] "WQUN84" "XX0GYV" "YP910X" "0V4SAC" "0X1RZ9" "3YHBC1" "55VDSQ" "653J82"
## [57] "6MEP2C" "76DIT4" "80KACX" "B2YJJP" "E3JP0C" "FLIZQI" "GM371F" "MEUZ85"
## [65] "PA9F3J" "SXSVEH" "TJN1AD" "WNKKW3" "XZH41H" "YDRD81" "Z25D52" "ZDRSG0"
## [73] "3P9BX6" "DGZLV3" "S63QDN" "ZW2X4N"We can also see the number of animals and the sex ratios created in each group.
lines <- sapply(sexRatioGrp$group, function(ids) {
paste0(
"Count: ", length(ids), " Sex Ratio: ",
round(calculateSexRatio(ids, trimmedPed), 2L)
)
})
for (line in lines) print(line)## [1] "Count: 35 Sex Ratio: 7.75"
## [1] "Count: 26 Sex Ratio: 7.67"
## [1] "Count: 25 Sex Ratio: 7.33"
## [1] "Count: 25 Sex Ratio: 7.33"
## [1] "Count: 35 Sex Ratio: 7.75"
## [1] "Count: 31 Sex Ratio: 9.33"
## [1] "Count: 103 Sex Ratio: 0.36"Examination of this table shows that of the 184 females 239 are included.
Pedigree Errors
As stated earlier you can see which types of errors are detected by qcStudbook by looking at names returned by getEmptyErrorLst() as shown below.
## [1] "failedDatabaseConnection" "missingColumns"
## [3] "invalidDateRows" "suspiciousParents"
## [5] "femaleSires" "maleDams"
## [7] "sireAndDam" "duplicateIds"
## [9] "invalidIdChars" "changedCols"Each is defined below.
| Error | Definition |
|---|---|
| failedDatabaseConnection | Database connection failed: configuration or permissions are invalid |
| missingColumns | Columns that must be within the pedigree file are missing. |
| invalidDateRows | Values, which are supposed to be dates, cannot be interpreted as a date. |
| suspiciousParents | Parents were too young on the date of birth of to have been the parent. |
| femaleSires | Individuals listed as female or hermaphroditic and as a sire. |
| maleDams | Individuals are listed as male and as a dam. |
| sireAndDam | Individuals who are listed as both a sire and a dam. |
| duplicateIds | IDs listed more than once. |
| invalidIdChars | IDs (id, sire, or dam) that contain a period (‘.’), which is not allowed. |
| changedCols | Columns that have been changed to conform to internal naming conventions and what they were changed to. |
We are going to use the small imaginary pedigree listed below that has multiple errors to discuss pedigree error detection and reporting. First note the birth dates of ego_id o4 (2006-04-13) and the purported sire s2 (2006-06-19). Note also the purported birth date of the d2 and the birth dates of her offspring. Obviously dates or IDs may be incorrect.
This is the pedigree. (We will discuss the column names shortly.)
| ego_id | sire.id | dam_id | sex | birth_date |
|---|---|---|---|---|
| s1 | NA | NA | F | 2000-07-18 |
| d1 | NA | NA | M | 2003-04-13 |
| s2 | NA | NA | M | 2006-06-19 |
| d2 | NA | NA | F | 2015-09-16 |
| o1 | s1 | d1 | F | 2015-02-04 |
| o2 | s1 | d2 | F | 2009-03-17 |
| o3 | s2 | d2 | F | 2012-04-11 |
| o4 | s2 | d2 | M | 2006-04-13 |
If we try to convert this pedigree file into the standardized studbook format, we are going to get an error message and the creation of a file in the R sessions temporary directory that lists the records that have generated the errors.
pedOne <- nprcgenekeepr::pedOne # put it in the local environment
ped <- qcStudbook(pedOne, minSireAge = 0.0, minDamAge = 0.0)## Error in `qcStudbook()`:
## ! Parents with low age at birth of offspring are listed in /tmp/RtmpYkZgqt/lowParentAge.csv.The contents of lowParentAge.csv is shown below.
| dam | sire | id | sex | birth | recordStatus | exit | sireBirth | damBirth | sireAge | damAge |
|---|---|---|---|---|---|---|---|---|---|---|
| d2 | s1 | o2 | F | 2009-03-17 | original | NA | 2000-07-18 | 2015-09-16 | 8.66 | -6.50 |
| d2 | s2 | o3 | F | 2012-04-11 | original | NA | 2006-06-19 | 2015-09-16 | 5.81 | -3.43 |
| d2 | s2 | o4 | M | 2006-04-13 | original | NA | 2006-06-19 | 2015-09-16 | -0.18 | -9.43 |
Examination of the ages of the parents reveals the issues being reported.
We can remove the errors by changing the birth dates of o4 from 2006-04-13 to 2015-09-16 and of d2 from 2015-09-16 to 2006-04-13.
pedOne$birth_date[pedOne$ego_id == "o4"] <- as.Date("2015-09-16")
pedOne$birth_date[pedOne$ego_id == "d2"] <- as.Date("2006-04-13")Note the changes made to the column names between the original pedOne pedigree and the pedigree (ped) we get from qcStudbook. We have chosen to limit the displayed pedigree by selecting the ego_id’s and id’s in pedOne and ped respectively.
ped <- qcStudbook(pedOne, minSireAge = 0.0, minDamAge = 0.0)
ped[ped$id %in% c("s2", "d2", "o3", "o4"), ]## id sire dam sex gen birth exit age recordStatus
## 2 d2 <NA> <NA> F 0 2006-04-13 <NA> 20.3 original
## 4 s2 <NA> <NA> M 0 2006-06-19 <NA> 20.1 original
## 7 o3 s2 d2 F 1 2012-04-11 <NA> 14.3 original
## 8 o4 s2 d2 M 1 2015-09-16 <NA> 10.8 originalHowever, the preferred method of creating the standardized studbook format with qcStudbook is to examine all errors found and correcting them before proceeding. This is done by explicitly requesting that all aspects inconsistent with the studbook format be identified by setting reportChanges and reportErrors to .
errorList <- qcStudbook(pedOne,
minSireAge = 0.0, minDamAge = 0.0, reportChanges = TRUE,
reportErrors = TRUE
)
summary(errorList)## Error: The animal listed as a sire and also listed as a female is: s1.
## Error: The animal listed as a dam and also listed as a male is: d1.
## Change: The column where period was removed is: sire.id to sireid.
## Change: The columns where underscore was removed are: ego_id, dam_id, and birth_date to egoid, damid, and birthdate.
## Change: The column changed from: egoid to id.
## Change: The column changed from: sireid to sire.
## Change: The column changed from: damid to dam.
## Change: The column changed from: birthdate to birth.
##
## Please check and correct the pedigree file.
## We will discuss each of these newly identified errors in a moment, however, let’s look at shortening this report, because often you will not be interested in the more trivial changes to the column names made by qcStudbook and in those cases you simply choose not to report changes to the column names as is shown here by setting reportChanges to . For this illustration, we are going to bring back the original copy of pedOne to see how the suspicious parents are reported by the summary function.
pedOne <- nprcgenekeepr::pedOne
errorList <- qcStudbook(pedOne,
minSireAge = 0L, minDamAge = 0L, reportChanges = FALSE,
reportErrors = TRUE
)
options(width = 90L)
summary(errorList)## Error: The animal listed as a sire and also listed as a female is: s1.
## Error: The animal listed as a dam and also listed as a male is: d1.
##
## Please check and correct the pedigree file.
##
## Animal records where parent records are suspicous because of dates.
## One or more parents appear too young at time of birth.
## dam sire id sex birth recordStatus exit sireBirth damBirth sireAge damAge
## 2 d2 s1 o2 F 2009-03-17 original <NA> 2000-07-18 2015-09-16 8.66 -6.5
## 3 d2 s2 o3 F 2012-04-11 original <NA> 2006-06-19 2015-09-16 5.81 -3.4
## 4 d2 s2 o4 M 2006-04-13 original <NA> 2006-06-19 2015-09-16 -0.18 -9.4The first two errors mentioned are of particular interest. Currently qcStudbook automatically changes the sex of dams to F (female) and sires to M (male) when reportErrors is set to .
Genetic Loops
This feature is not supported within the Shiny application and is not fully implemented.
To use the findLoops function run the following code and select a pedigree as your input file that has a loop in it. We are continuing to use the example pedigree that comes with the software Example_Pedigree.csv.
exampleTree <- createPedTree(breederPed)
exampleLoops <- findLoops(exampleTree)You can count how many loops you have with the following code.
length(exampleLoops)## [1] 3694
nLoops <- countLoops(exampleLoops, exampleTree)
sum(unlist(nLoops[nLoops > 0L]))## [1] 258You can list the first 10 sets of ids, sires and dams in loops with the following line of code:
## id sire dam
## 2519 V49H3Y UFI88T 9T7Y2Z
## 2572 61FUGE UDQ5WC GL88CF
## 2695 LWJ3A5 KZM9RB GCBYDW
## 2722 RNQU14 H2RDE2 DKIM6U
## 2752 L9M1DC 3PU50K WFQENR
## 2755 Q8U9LB 3PU50K CLSVU6
## 2905 FVJ14K UXC40T L5VC2M
## 2922 531HAC UMV4BE 5DIPZN
## 2924 85ESBB UQFY9C Q2RK1E
## 2941 0VLW56 6KPKH7 MMEHXV
elapsed_time <- get_elapsed_time_str(start_time)The current date and time is 2026-07-15 14:50:08.092641. The processing time for this document was 20 seconds..
## R version 4.6.1 (2026-06-24)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.4 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## Random number generation:
## RNG: Mersenne-Twister
## Normal: Inversion
## Sample: Rounding
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
## [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
## [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
##
## time zone: UTC
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices datasets utils methods base
##
## other attached packages:
## [1] nprcgenekeepr_2.0.0 knitr_1.51 ggplot2_4.0.3 stringi_1.8.7
##
## loaded via a namespace (and not attached):
## [1] gtable_0.3.6 anytime_0.3.13 xfun_0.60 bslib_0.11.0
## [5] htmlwidgets_1.6.4 lattice_0.22-9 vctrs_0.7.3 tools_4.6.1
## [9] generics_0.1.4 tibble_3.3.1 pkgconfig_2.0.3 Matrix_1.7-5
## [13] data.table_1.18.4 checkmate_2.3.4 RColorBrewer_1.1-3 S7_0.2.2
## [17] desc_1.4.3 readxl_1.5.0 lifecycle_1.0.5 compiler_4.6.1
## [21] farver_2.1.2 stringr_1.6.0 textshaping_1.0.5 Rlabkey_3.5.0
## [25] httpuv_1.6.17 htmltools_0.5.9 sass_0.4.10 yaml_2.3.12
## [29] htmlTable_2.5.0 later_1.4.8 pillar_1.11.1 pkgdown_2.2.1
## [33] jquerylib_0.1.4 DT_0.34.0 cachem_1.1.0 sessioninfo_1.2.4
## [37] mime_0.13 tidyselect_1.2.1 zip_3.0.1 digest_0.6.39
## [41] dplyr_1.2.1 labeling_0.4.3 fastmap_1.2.0 grid_4.6.1
## [45] cli_3.6.6 magrittr_2.0.5 withr_3.0.3 scales_1.4.0
## [49] promises_1.5.0 backports_1.5.1 plotrix_3.8-14 lubridate_1.9.5
## [53] timechange_0.4.0 rmarkdown_2.31 lambda.r_1.2.4 httr_1.4.8
## [57] otel_0.2.0 futile.logger_1.4.9 cellranger_1.1.0 ragg_1.5.2
## [61] openxlsx_4.2.8.1 shiny_1.14.0 evaluate_1.0.5 rlang_1.3.0
## [65] futile.options_1.0.1 Rcpp_1.1.2 xtable_1.8-8 glue_1.8.1
## [69] formatR_1.14 renv_1.2.3 rstudioapi_0.19.0 jsonlite_2.0.0
## [73] R6_2.6.1 systemfonts_1.3.2 fs_2.1.0